As you might be aware right now I’m currently working on revamping the GDScript compiler. After finishing the tokenizer in the last report, I’ve been working on the new parser.
The main point to bring in this rewrite is to make a bit more “textbook-like” as mentioned in the previous article, so I split grammar production in different functions. Before we had big switch statements with many cases to parse the code, now we delegate the work to specific functions. This makes it easier to find where a particular piece of code is.
See other articles in this Godot 4.0 GDScript series:
- GDScript progress report: Writing a tokenizer
- (you are here) GDScript progress report: Writing a new parser
- GDScript progress report: Type checking is back
- GDScript progress report: New GDScript is now merged
- GDScript progress report: Typed instructions
- GDScript progress report: Feature-complete for 4.0
Less lookahead
The previous parser relied on the tokenizer ability to buffer tokens to ask for a few the next (and sometimes the previous) tokens in order to decide what the code means. The new tokenizer lacks this ability on purpose to make sure we can use the bare minimum of a lookahead to parse the code.
Minimizing lookahead means the code is easier to parse. If we were to introduce a new syntax for a feature, now we have to make sure it does not increase the complexity of the parser by demanding too much tokens at once.
The new parser only stores the current and previous token (or the current and the next if you look it in another way). It means that GDScript only needs one token of lookahead to be fully parsed. This takes us to a simpler language design and implementation.
A Pratt parser for expressions
Those who are familiar with programming language implementation will know that parsing expressions is always tricky. When you consider precedence of operators, and that an arbitrary expression can be left operand of a, say, + operator, it can get very tricky to decide how to build the parse tree.
There are different solutions to this but I like the Pratt parsing for its simplicity. It consists in a function table in which the index is the token type. This means that deciding which parser function to call is just a lookup based on the current token.
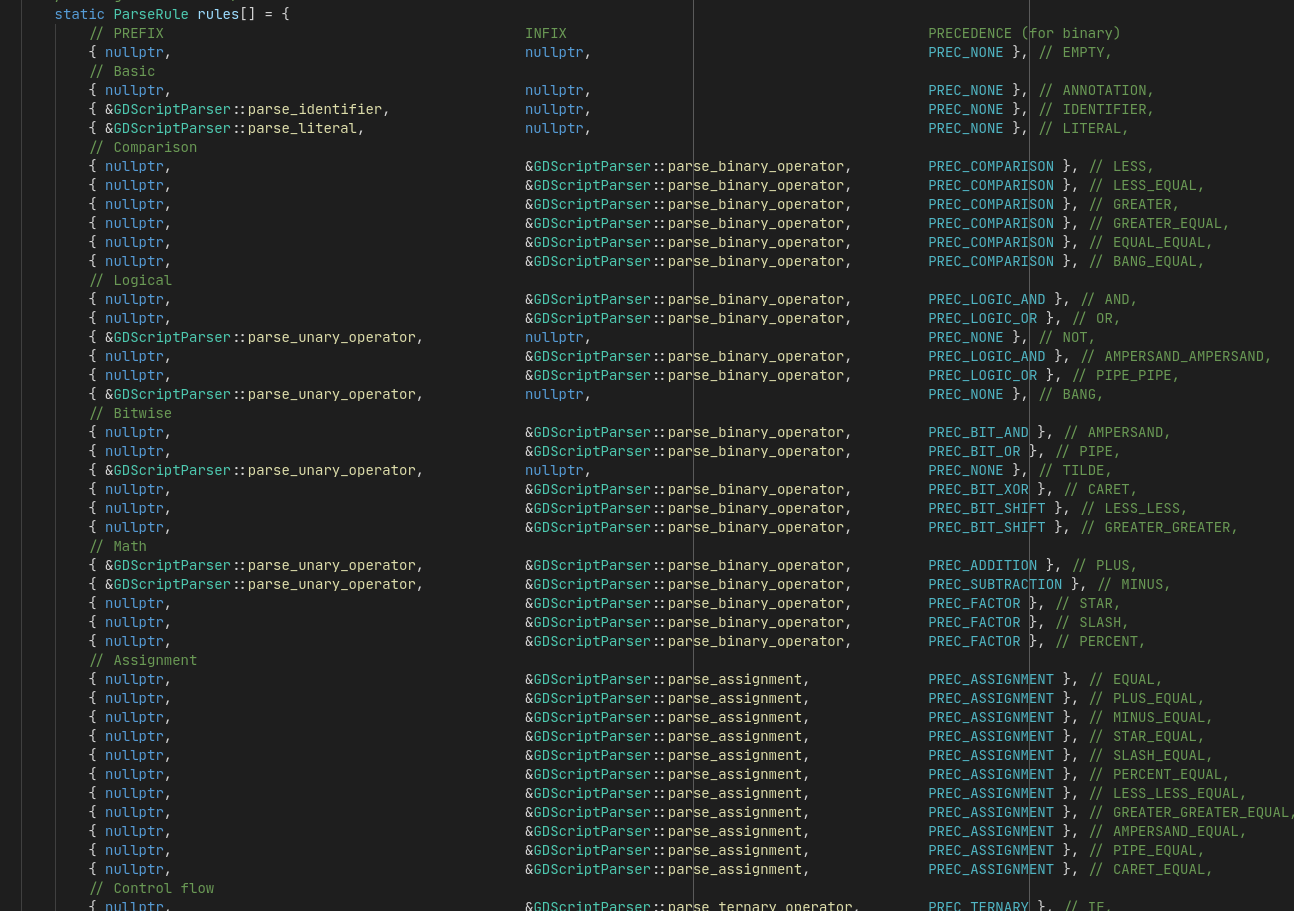
This makes it very easy to see—and change—the precedence of every operators. The functions do have to share the signature, but it’s usually not a big deal since most of them aren’t called outside the expression parser.
Multiple error detection
Also mentioned in the previous article, the idea is to show multiple errors at once so you don’t need to fix one to discover the next. The new parser has support to store an arbitrary number of errors.
When it finds something unexpected, the parser enters “panic mode”. While in this mode, it will ignore every token until it finds one that can only be the beginning of a statement. At this point, it can leave the panic mode and go back to regular parsing. While this can cause cascading errors due to missing or extra token, it can show errors in different parts of the file at once.
This will also help completion since the parser won’t need to stop on the first error and can check what’s next in the file to also suggest.
Pretty tree printer
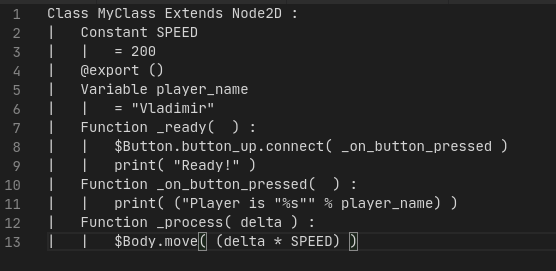
As I did with the tokenizer, I added a print mode to replace the old gd_parser test. It prints the tree in an unambiguous readable way so problems with parsing can be detected.
So a script like this:
class_name MyClass extends Node2D
const SPEED = 200
@export var player_name = "Vladimir"
func _ready():
$Button.button_up.connect(_on_button_pressed)
print("Ready!")
func _on_button_pressed():
print("Player is \"%s\"" % player_name)
func _process(delta):
$Body.move(delta * SPEED)
Will be printed like this:
Class MyClass Extends Node2D :
| Constant SPEED
| | = 200
| @export ()
| Variable player_name
| | = "Vladimir"
| Function _ready( ) :
| | $Button.button_up.connect( _on_button_pressed )
| | print( "Ready!" )
| Function _on_button_pressed( ) :
| | print( ("Player is "%s"" % player_name) )
| Function _process( delta ) :
| | $Body.move( (delta * SPEED) )
Annotations
Shown briefly in the previous example, I implemented annotations as outlined in GIP #828. Those are meant to replace a few keywords and improve the ability to add new integrations without having to create new keywords and big changes in the parser.
This also means that the old export syntax is now extinct in favor of specific annotations. This makes it in general easy to remember and understand and don’t require much effort in the GDScript implementation, since their arguments are the same as expected in the internal hint strings.
There will be an update to the documentation to explain the new way.
await replaces yield
The old yield syntax was a bit convoluted complicated to understand, forcing you to deal with function states. It was especially harder to understand given it did the opposite of other languages do with the same keyword.
The await syntax can be used to wait for signals or coroutines alike:
func coroutine():
await $Button.button_up # Will suspend the function and resume when the button is pressed.
return true
func _ready():
var result = await coroutine() # Will suspend the function and wait for the coroutine result.
print(result) # true
Breaking things to make them anew
I wanted to make this new parser working with the current system sooner rather than later. So I amended the dependencies on the old parser and tokenizer to use the new one. Since this is rather time consuming, a lot of things were disabled in the meantime.
I do mention what’s missing in my initial Pull Request but here is a shortlist:
- Type checking.
- Code completion.
- Warnings.
- Language server.
setget(will be replaced by properties).- Some optimizations.
This will be fixed in the next steps
Future
There’s still a long road ahead to make GDScript a better language in general. The next step is to read the type checks so the systems that depend on it can also be reactivated. Hopefully the new type checker will be more precise than the previous one (I learned a lot since then). And it will allow use of some new features like typed arrays.