
After completing the new tokenizer and parser as mentioned in the previous reports, I started working on the code analyzer, which is responsible for type checking and also for used for other features like warnings and some optimizations.
This was done before as a second pass inside the parser but it was now moved to another class to make it clear that it doesn’t happen at the same pass thus avoiding issues with functions being called out of order (which happened by a few contributions that missed this detail).
See other articles in this Godot 4.0 GDScript series:
- GDScript progress report: Writing a tokenizer
- GDScript progress report: Writing a new parser
- (you are here) GDScript progress report: Type checking is back
- GDScript progress report: New GDScript is now merged
- GDScript progress report: Typed instructions
- GDScript progress report: Feature-complete for 4.0
Inferred by default
One of the main changes in the new type checker is that it always infer the type of expressions and variables. It does not force the variable type unless explicitly stated by the user, as it was before, but it’s now able to catch type errors in these cases, and potentially optimize based on types.
This also means that it’s easier to get safe lines (the ones colored in green) even without adding types to everything and more errors can be detected at the editor.
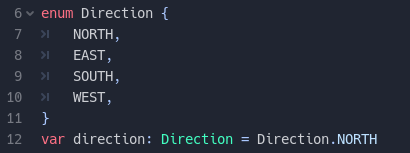
Enums can be used as types
A long requested feature is that enums should be also possible types. They are considered regular integers in general, but for type checking purposes they are considered a specific type. For example, setting an integer to a variable with an enum type is okay but setting from a different enumeration gives an error.
Warnings are back
The code was moved to a different file to avoid issues with circular includes. It also helps uncluttering the main gdscript.cpp file which is already long enough.
Some warnings were removed since they don’t apply to the new GDScript syntax, such as the one about the possibility of a yield which is not a concern anymore since the keyword is replaced by await. Some were added to cover new ground, like a warning for unused local constants, since those are now added.

Local identifiers are now better checked for usages and shadowing. So the iterator variable from a for loop or the binds in a match statement are treated like local variables and have the checks applied to them as well. This means that if you try to declare a variable with the same name as a match binding, you’ll get an error and if you don’t use the binding you’ll get a warning.
Better constant folding
The process of analyzing constant expressions and processing their result at compile time is commonly called “constant folding”. The old parser did that in the first pass (since it dated from back when GDScript had a single parser pass) but now it is done by the analyzer.
This means that now it’s possible to resolve constant names as well in all cases. For instance, if you type PI * 2 in your code, the analyzer will compute the multiplication at compile time, increasing a bit of performance at runtime. This also applies to user-defined constants, which reduces the burden of using those to replace common values.
GDScript cache singleton for mediating loading of scripts
Last year I’ve come up with an idea to cache scripts in order to fix the problems with cyclic dependencies in GDScript. I’ve made a pull request for the 3.2 branch but unfortunately it’s still lacking in some regards.
The idea is to allow only parsing the scripts without using the Resource Loader from Godot itself. This makes possible for the code to do type checking from dependencies without creating a loading loop. It also creates “shallow scripts” (that is, scripts that still don’t have the code compiled) so they can be referenced before being actually compiled.
I’m now integrating this idea with the new GDScript code to solve the problem from the root. Once it’s working I’ll also port it back to 3.2, as long as we can test it thoroughly to avoid regressions.
Properties syntax
As mentioned in the previous report, my intention is to remove setget and provide a more straightforward property declaration instead. This is now done with the addendum that lets users still use regular functions as setter and getter if so they wish.
Code completion
The code completion relies on the parser code, so the old version was removed. I’m now working on porting it to the new parser while adding extra completion needed in some cases, like enums in type hints, and completion for annotations names and arguments. This is still a work in progress so far.
Future
As mentioned, I still need to finish code completion. After that I’ll make a new PR since the code will be in a usable status, with GDScript having the same level of features as before (or more in some areas). This will allow the users to begin testing and we can fix potential bugs that I missed in my tests.
Afterwards I’ll start working on the interpreter to start doing performance optimizations.