Some of you may not be aware, but I’m currently rewriting GDScript. It was discussed during the last Godot Sprint in Brussels and the core developers approved the idea.
The main rationale to rewrite the GDScript implementation is that it has been changed so much that it’s gotten quite hard to understand after receiving so many new features. This is also an opportunity to clean up, tidy up, and modernize the code, like it happened for some other parts of the engine that got rewritten in the past years.
The objective is to have a more “textbook-like” compiler, which will help maintenance both by those already acquainted with the Godot source and by new faces who saw something about writing compilers in the past. Hopefully this will make it harder to mess something up, given this is critical code for the engine users.
See other articles in this Godot 4.0 GDScript series:
- (you are here) GDScript progress report: Writing a tokenizer
- GDScript progress report: Writing a new parser
- GDScript progress report: Type checking is back
- GDScript progress report: New GDScript is now merged
- GDScript progress report: Typed instructions
- GDScript progress report: Feature-complete for 4.0
Why not a parser generator?
I’ve seen this question more than once: why can’t we use a parser generator? Then we would just need to write a grammar specification and the generator makes the whole parser for us.
The main problem with parser generators—and the main reason modern language compilers don’t use them—is that it is incredibly hard to provide meaningful error messages to the users of the language. With hand-made parsers we can inject checks, such as properly validating the path you put in a preload statement, among other things.
The GDScript grammar is also pretty much settled (except maybe for a few of the new features) so we don’t benefit from prototyping and iterating on a grammar definition, which is the main selling point of parser generators.
Rewriting the tokenizer
The first step when writing a compiler is to make the tokenizer (also called scanner by some authors). It has the responsibility of reading the characters of the source code and bundling them together as meaningful chunks which are called tokens. Tokens contain information about what they mean and where they occured. This makes the following compilation steps easier to manage as they don’t have to deal with minutiae such as comments and whitespace, which are not meaningful for the final execution.
I’m taking this opportunity to make the tokenizer a bit smarter (and maybe a bit dumber in some regards) in order to make the parsing simpler (I’ll write about the parser when I get there). The new tokenizer will emit special tokens when it detects there’s an indentation change and also a newline. Since GDScript is indentation based, this helps the parser identify the start and end of blocks. This approach is also used by Python, so I’m not being revolutionary here.
I’m also rewriting the --test gd* commands so they work with the new code. Those are very useful during this rewrite since they allow me test the steps of the compiler without needing to have everything ready. I can make sure the tokenizer is working properly before moving on to the parser.
What is a token?
A token is a data container which describes the characters in the source code as something meaningful for the programming language. The main thing to store is the token type (e.g. a symbol, an identifier, a keyword, etc.), which is a value taken from an enum, since there are limited variety. This is used by the parser to understand which statement to expect.
Another thing is the potential associated data. If it’s, say, a + sign it doesn’t matter since the type Token::PLUS is enough to recognize it, but a Token::IDENTIFIER needs to have the actual identifier to be referred. Literal values, such as numbers and strings, also need to be stored. The new tokenizer uses a single Variant to store this.
It’s also useful to store positional information about the token: line/column where it starts and ends. This is not useful for interpreting the code, but is incredibly valuable for creating readable error messages.
Features of the new tokenizer
As mentioned, the main reason for the rewrite is to make it smarter, so let me show off some of the new features.
Storing correct positional data
The old tokenizer stored only line and column, but there are many tokens that span across many columns and some across multiple lines. For example, a snippet like this one:
var x = "string"
x += """\
Multiline String
"""
Can now be tokenized like this:
0001 var x = "string"
^^^
--> var
-------------------------------------------------------
0001 var x = "string"
^
--> Identifier(StringName) x
-------------------------------------------------------
0001 var x = "string"
^
--> =
-------------------------------------------------------
0001 var x = "string"
^^^^^^^^
--> Literal(String) string
-------------------------------------------------------
0001 var x = "string"
^
--> Newline
-------------------------------------------------------
0002 x += """\
^
--> Identifier(StringName) x
-------------------------------------------------------
0002 x += """\
^^
--> +=
-------------------------------------------------------
0002 x += """\
0003 Multiline String
0004 """
^^^^^^^^^^^^^^^^
--> Literal(String) Multiline String
-------------------------------------------------------
0004 """
^
--> Newline
-------------------------------------------------------
EOF
This is actually the output of the new tokenizer test. It rewrites the lines and points to the whole span of the token. This is meant to improve error messages by pointing the user to the exact spot.
Creating indentation and newline tokens
While the previous tokenizer kept track of indentation characters and newlines, it let the parser decide the current indentation level, and whether or not a newline was relevant. The new one only generates a newline token when it’s not empty, and also emits tokens for indentation. For example:
"start"
"indent"
"more indent"
"two dedents"
Is tokenized like this:
0001 "start"
^^^^^^^
--> Literal(String) start
-------------------------------------------------------
0001 "start"
^
--> Newline
-------------------------------------------------------
0003 "indent"
^^^^
--> Indent
-------------------------------------------------------
0003 "indent"
^^^^^^^^
--> Literal(String) indent
-------------------------------------------------------
0003 "indent"
^
--> Newline
-------------------------------------------------------
0004 "more indent"
^^^^^^^^
--> Indent
-------------------------------------------------------
0004 "more indent"
^^^^^^^^^^^^^
--> Literal(String) more indent
-------------------------------------------------------
0004 "more indent"
^
--> Newline
-------------------------------------------------------
0005 "two dedents"
^
--> Dedent
-------------------------------------------------------
0005 "two dedents"
^
--> Dedent
-------------------------------------------------------
0005 "two dedents"
^^^^^^^^^^^^^
--> Literal(String) two dedents
-------------------------------------------------------
0005 "two dedents"
^
--> Newline
-------------------------------------------------------
EOF
You can see that it detects a decrease in two levels by emitting two dedent tokens. It also doesn’t emit a newline on line 2 because it’s empty.
Error reporting and leniency
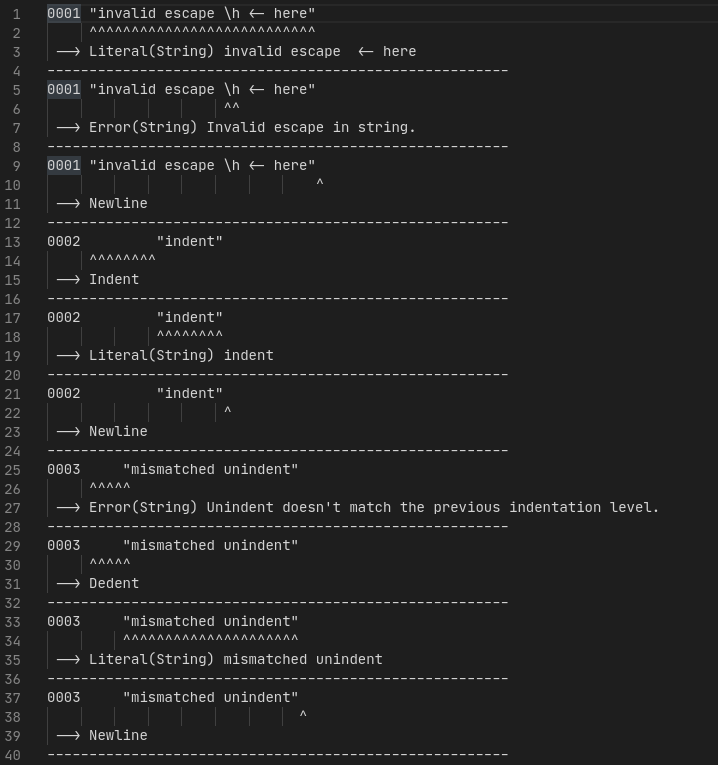
The old tokenizer only allowed for one error, after which it would only return the same error if you asked for a new token. Now it returns the error but keeps going through the process so you can detect many errors at once. So this:
"invalid escape \h <- here"
"indent"
"mismatched unindent"
Gives this:
0001 "invalid escape \h <- here"
^^^^^^^^^^^^^^^^^^^^^^^^^^^
--> Literal(String) invalid escape <- here
-------------------------------------------------------
0001 "invalid escape \h <- here"
^^
--> Error(String) Invalid escape in string.
-------------------------------------------------------
0001 "invalid escape \h <- here"
^
--> Newline
-------------------------------------------------------
0002 "indent"
^^^^^^^^
--> Indent
-------------------------------------------------------
0002 "indent"
^^^^^^^^
--> Literal(String) indent
-------------------------------------------------------
0002 "indent"
^
--> Newline
-------------------------------------------------------
0003 "mismatched unindent"
^^^^^
--> Error(String) Unindent doesn't match the previous indentation level.
-------------------------------------------------------
0003 "mismatched unindent"
^^^^^
--> Dedent
-------------------------------------------------------
0003 "mismatched unindent"
^^^^^^^^^^^^^^^^^^^^^
--> Literal(String) mismatched unindent
-------------------------------------------------------
0003 "mismatched unindent"
^
--> Newline
-------------------------------------------------------
0004
^
--> Dedent
-------------------------------------------------------
EOF
You can notice that the error in the string comes after the string token. That’s okay because the parser will report all errors at once and they will be sorted by position.
Indentation level is also correctly maintained even in case of a mismatch (that’s why there’s two dedents for one indent). This is helpful to keep the parsing lenient in some special cases, which I’ll talk more about when I write about the parser.
Recognizing extra tokens
Some characters and sequences aren’t allowed in the source code but they can be tokenized so a better error message can be provided. Example:
? ` <<<<<<< ======= >>>>>>>
Result:
0001 ? ` <<<<<<< ======= >>>>>>>
^
--> ?
-------------------------------------------------------
0001 ? ` <<<<<<< ======= >>>>>>>
^
--> `
-------------------------------------------------------
0001 ? ` <<<<<<< ======= >>>>>>>
^^^^^^^
--> VCS conflict marker
-------------------------------------------------------
0001 ? ` <<<<<<< ======= >>>>>>>
^^^^^^^
--> VCS conflict marker
-------------------------------------------------------
0001 ? ` <<<<<<< ======= >>>>>>>
^^^^^^^
--> VCS conflict marker
-------------------------------------------------------
0001 ? ` <<<<<<< ======= >>>>>>>
^
--> Newline
-------------------------------------------------------
EOF
The question mark can be recognized as an attempt to use the C-style ternary conditional operator, so we can show the user the correct operator for GDScript.
We also recognize conflict markers so you can easily notice that you have a merge conflict in the file.
What comes next
Now that the tokenizer is pretty much done, I’ll start rewriting the parser, which is responsible for reading the sequence of tokens and making sense out of them, deciding if it’s a function, variable, expression, etc. I’ll write more about it when I have something to show.